JavaScript in Context
The goal of this post is not to teach JavaScript, but to explain key concepts and some historical context around them. If you are looking to learn JavaScript itself, MDN is a high-quality resource to learn from.
Additionally, there are plenty of guides that will jump into writing your first React app or using a particular dataviz library. JavaScript is similar enough to languages like Python that you can likely jump in to those tutorials without knowing the language well.
However, if you start with something like the d3.js documentation you’ll quickly be confronted with acronyms like CDN, ESM, and UMD. Pursuing answers to what those are will likely lead you to mentions of the DOM, ES, AJAX, and npm. And what exactly is node? Or React?
JavaScript that is written for the browser works very differently from code that you execute from your terminal or by running a local application. So despite the familiar syntax, there’s a lot of context that is useful in understanding how to write JavaScript for the web.
This document explores that context and the JavaScript ecosystem, first by explaining the unique origins of JavaScript, its rapid evolution in the last decade or so, and should help to give a sense of where JavaScript is today and how you might approach it for different needs.
What is JavaScript?
JavaScript is a programming language introduced in 1995 as a feature of the dominant web browser of the era, Netscape.
At the time, a webpage was typically a straightforward document or form. Web pages were written entirely in static HTML, meaning that whatever loaded when you visited a URL was what you got— the arrangement of words & images on the page didn’t change after the page was loaded from the server. Allowing programmers to write code that ran in the browser would mean that pages could have interactive elements, someone could dynamically alter the contents of a page, creating more interactive experiences: maybe a simple game or spreadsheet app.
A few facts about that first version:
The original version of the language was written by one person, and it took 10 days. That is both an impressive feat, but also an indication of the level of planning that went into that first version. In 1995 nobody foresaw what the web would become and the role that JavaScript would play. That is important because it results in a lot of the shortcomings we’re left with 30 years later.
The name JavaScript was essentially a marketing term. The language has no formal relationship to Java, which at the time was emerging as an important language. Java is closer to C++ or C# in semantics and purpose, a compiled language used for building applications. Java is a by-the-book object oriented language, and Javascript is, as we will see, definitely not.
JavaScript borrowed heavily from more obscure origins, Self and Scheme. It is from these that it gets two of its most unique characteristics: prototypal inheritance, and a wealth of functional programming features.
Prototypal Inheritance
// Constructor function instead of a class definition.
// A function that adds attributes to an implicit "this" object.
function Person(name, age) {
this.name = name;
this.age = age;
}
// Add methods on the prototype means all future instances
// will have this method.
// Contrast this to Python where once a class is defined you cannot
// (easily) add new methods to it
Person.prototype.greet = function() {
console.log(`Hello, my name is ${this.name} and I'm ${this.age}.`);
};
// Create instances of Person using "new Funcname", which initializes
// the implicit "this"
const person1 = new Person('Sergei', 25);
const person2 = new Person('Alice', 30);
// instances get the methods shared by the prototype
person1.greet(); // Output: Hello, my name is Sergei and I'm 25.
person2.greet(); // Output: Hello, my name is Alice and I'm 30.
This is prototype-based inheritance. It is a form of object-oriented programming, but not the one chosen by C++, Java, Python, C#, Ruby, etc. Lua is probably the next most common language with similar semantics.
Functional Programming
Functional programming is a paradigm like OOP and procedural programming. It emphasizes the composition & application of functions.
Procedural programming typically makes use of variable assignment, if statements, and for loops:
def sum_of_squares_of_evens(numbers):
total = 0
for num in numbers:
if num % 2 == 0:
total += num ** 2
return total
Functional programming favors an approach based in applying chains of functions:
def sum_of_squares_of_evens(numbers):
return sum(map(lambda x: x ** 2, filter(lambda x: x % 2 == 0, numbers)))
Or the more pythonic (but still functional) equivalent:
def sum_of_squares_of_evens(numbers):
return sum(num ** 2 for num in numbers if num % 2 == 0)
I’ve shown these examples in Python because Python too has a strong functional influence, but allows for procedural and object-oriented code. That is the nature of the most successful languages today, they are all multi-paradigm, supporting a blend of OO, functional, and procedural code.
JavaScript too is multi-paradigm, though is much more friendly to functional programming than Python, though an exploration of that dives deeper into JavaScript syntax than I intend to do here.
Functional Programming 101 by Cassidy Williams introduces functional programming concepts in JavaScript if you’d like to pursue that further.
JavaScript and the Browser
JavaScript mostly stays a browser-only language for the next 15 years.
That is to say, nobody was doing something like this:
$ javascript my-script.js
executing JS from the command line the way you would with Python or Ruby.
Instead, JavaScript was running in a unique environment:
<html>
<body>
<h1>HTML!</h1>
<!-- this is an HTML comment -->
<script type="text/javascript">
// this is a JS comment
// code inside this script tag will run when the tag loads
document.getElementsByTagName("h1")[0].innerHTML = "JavaScript!"
// this code finds the h1 tag on the page and replaces HTML!
// with JavaScript!
</script>
</body>
</html>
This is JavaScript executing within the context of the browser, specifically as part of an HTML page.
Sandboxing
Of course, HTML is typically downloaded via HTTP.
That means a web server sends your browser a chunk of HTML and your browser turns that into a webpage you can read & interact with.
HTML alone poses no real harm, it can only present content, but now executable code is being sent over the network and your computer is expected to execute it without even showing it to you first.
What if someone sends the equivalent of os.system("rm -rf /")?
If that sounds scary, it should!
To cut down on the risks here, JavaScript in the browser runs “sandboxed”, meaning it can’t access key parts of your operating system: your local disk is off limits. The browser can store things (mostly cookies) there, and JavaScript may request to read or write to these, but in a much more limited way than being able to open any file on your drive the way the default Python runtime can. (I’ll talk more about runtimes when we get to node.js in a later section.)
Early JavaScript was incredibly restricted, there wasn’t even the equivalent of a “print” statement.
JavaScript apps mostly popped up alert() boxes like this since print wasn’t an option:
Document Object Model (DOM)
Instead of printing to a terminal, JavaScript programs manipulate the structure and content of the HTML on the page. This simple idea opens up a ton of possibilities, and the key innovation that drives it is referred to as the document object model or the DOM.
The DOM refers to the way that the HTML tree can be browsed and manipulated via an underlying document object that all JavaScript running in the browser can access.
It exists as a global variable each JavaScript program can access and manipulate.
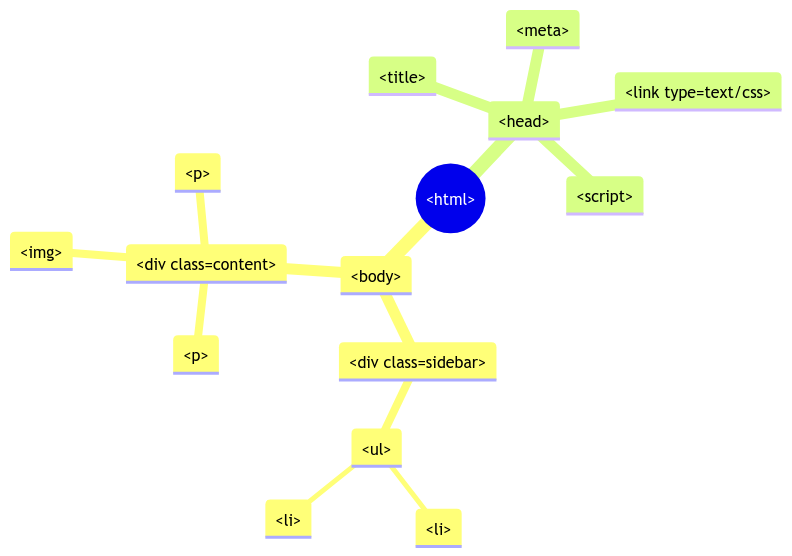
HTML parses into a tree. If you’ve done web scraping, you’ve navigated this tree via XPath or CSS selectors.
The original DOM implementation predates XPath and CSS selectors. Instead you would use:
// iterate through the divs one at a time
document.getElementsByTagName("div");
// navigate by position in tree
document.documentElement.firstChild.nextSibling.nextSibling;
In the context of the browser, JavaScript code can always rely upon the document existing, since there was no JavaScript outside of an HTML document.
Browser Differences & ECMAScript
JavaScript didn’t say confined to Netscape. Soon other browsers like Internet Explorer had their own versions (JScript), without cooperation, each web browser developed a unique implementation of the language. These implementations were more-or-less compatible, but not perfectly.
While there was some core agreement (generally speaking, the syntax didn’t differ), each browser would add custom methods and attributes to their DOM implementations and browser APIs.
This issue persists today, though it was reined in a bit when JavaScript became a standard, ECMA-262.
ECMA is a standards organization, the European Computer Manufacturers Association.
This is where JavaScript gets the alternate name ECMAScript, which is now often abbreviated to ES.
A large portion of the JavaScript community prefers ES as a name, and quite a few tools use it as a prefix (e.g. eslint, esbuild).
Of course, standardization didn’t solve the problem overnight. The language was standardized in 1997, updated in 1998 and 1999 and then languished for nearly a decade. After several failed attempts at an ES4 specification fell apart in 2003, no new version was ratified until 2009.
AJAX
Most languages that went a decade without a formal revision would have been replaced. Especially ones as flawed as early JavaScript. But with browser manufacturers competing and not wanting to break backwards compatibility with the web, their only choice was to extend the language.
So what happened next? Browser differences exploded, if you do not recall, it was not uncommon to see sites in the 2000s that only worked in Internet Explorer 6 or Netscape 4.

IE6’s JS differences were a part of that, along with other Microsoft-specific technologies.
These features often pushed against the narrow sandbox that JavaScript had been given to play in, increasing the utility of the language while also drastically increasing the risk of running other people’s code on your machine.
One of these was the XMLHttpRequest API added by Microsoft to support an early version of Outlook Web Access.
This new feature meant that web pages could make additional HTTP requests behind the scenes, loading dynamic content. Prior to this the interactivity of a page was largely limited to manipulating the content that was already there, now almost anything was possible via updating small portions of the page at once without the time and visual impact of reloading the entire page.
Traditional HTTP Request
sequenceDiagram
autonumber
browser->>web server: GET /index.html HTTP/1.1
web server->>browser: ...200 OK <html>
browser->browser: render
browser->>web server: POST /login HTTP/1.1
web server->>browser: ...200 OK <html>
browser->browser: re-render
Each request generates a new response, and the browser reloads the page each time.
With AJAX
sequenceDiagram
autonumber
browser->>web server: GET /index.html HTTP/1.1
web server->>browser: ...200 OK <html>
browser->browser: render
browser->>web server: XMLHttpRequest(POST, /login, payload)
web server->>browser: json | data={"success": ...}
browser->browser: handleResponse(data)
While the graphs look the same and achieve similar results, at step 4 things diverge. The request is sent via JS, in the background, instead of the browser URL bar, avoiding a page reload.
At step 5, JSON is returned, containing just the information that the site needs to update.
At step 6, the page is updated via a JS function handleResponse, instead of reloading the entire page.
This new paradigm became known as “AJAX” or “Asynchronous JavaScript and XML1.”
Aside: I was pretty confused when I started hearing about AJAX as a rookie programmer. I was not a JS person (few were) and couldn’t find a definition I could follow, they all seemed too simple or too complex. I eventually bought a book with “AJAX Programming” in the title. I was annoyed when I realized I’d bought an entire book on how to make an HTTP request from JavaScript. It is a deceptively simple idea, and at the time the book did a terrible job of explaining the importance it’d have.
You may recall that when you enter a URL into your browser, it makes an HTTP request, if that page returns references to other resources (images, video, external JS or CSS) they too will be fetched. Once the full page loaded, images and all, that’d be it.
XMLHttpRequest changed that by allowing web pages to fetch more information via JavaScript. This means a web page could:
- load new content when a button was pressed without reloading the page
- dynamically load new content on a timer, or when the user scrolls, or when some event happens
If you’ve opened your browser’s Web Console and seen requests flying by, messages being printed to the terminal, etc. that is all because of this change. Pages today are dynamic sites, with continuously running JavaScript. Graphics animate, ads load, entire interactive applications exist that do not remotely resemble the “documents” that the web was originally built to support.
With this new functionality, the web changed in major ways.
The biggest problem: JavaScript was slow and now had some pretty serious security vulnerabilities. Increased complexity meant more people finding ways to break out of the sandbox, and pulling data from other pages where they shouldn’t be able to.
This renewed effort also finally got the ECMAScript standards body moving again.
Since 2015, annual revisions are made, and a formal process exists for proposing changes to the language.
Lots of these revisions add features seen in currently-evolving languages like Python and Rust. Recent versions have added iterators and generators, an improved for loop, async programming, and other features that make Javascript a much nicer language to write than it was a decade or so ago.
If you’d like to see how the language evolves, the best lightweight “changelog” I can find is the ECMAScript version history Wikipedia page.
Aside: Still Broken?
I learned JavaScript around the time that Douglas Crockford, creator of JSON, released a book titled “JavaScript: The Good Parts”. The book was a brisk 153 pages, compared to the ~700 page “rhino book”. That ratio summed up a lot of people’s feelings about the language.
Since then JavaScript has matured, and with annual revisions the “good parts” now probably outweigh the bad, but for reasons we’ll get to momentarily, the language has some serious flaws that are not likely to be fixed.
So, if annual revisions are being made, why is JS still filled with annoying gotchas?
For instance:
console.log(1 + "2"); // 12
console.log(true + 1) // 2
This is… surprising.
Also,
console.log(1 == "1"); // Output: true
console.log(0 == false); // Output: true
This is because in JS == does type coercion, while === does not. Yes, that means the correct operator to use most of the time is ===.
These persist because they cannot be fixed. Not without breaking the web.
Where a language like Python could decide to make a sweeping change (the behavior of / changed between Python 2 and 3 for instance), JavaScript is bound by a curse that comes with working on the web: a very strong dedication to ensuring backwards compatibility.
This means new ES versions can mostly only add to the language, rarely modify or retract. Enough code depends on these behaviors now that it seems unlikely that things as fundamental as operators can be repaired.
This is largely remedied today by a strong culture of using linters that detect these common mistakes. You likely want to use eslint and prettier which can be configured in your editor.
Escaping the Browser
V8
ES, like Python, is a language, a set of rules about what the syntax means and, in the case of browser-bound ES it comes with a set of pre-defined methods and objects like the aforementioned document and XMLHttpRequest.
We call this a runtime environment, commonly shortened to runtime.
Language runtime environments are specific language implementations packaged along with additional APIs, like how IE5 introduced XMLHttpRequest.
That means Chrome has an ES runtime and Firefox has a different ES runtime, as does Safari, Edge, etc. In fact each version of these browsers would have a slightly different version, exposing new features to the underlying JavaScript code. Think about how your browser can now prompt you to give it access to your webcam, location, etc. These are all runtime features.
All of this meant increased security concerns and a need for improved performance to scale with the growing use of JS. Google Chrome introduced a runtime they call V8 in 2009 aimed at solving both problems.
This runtime could be orders of magnitude faster than any ES runtime that came before it. This meant that applications like Google Docs & gmail could run incredibly fast and feel like native desktop applications. It was also designed in a way that strengthened the security profile, making it nearly impossible for applications to access one another’s memory.
Today most browsers have adopted V8 or something like it, so JavaScript can run very efficiently and enormous JS-laden applications are possible.
Node.js
Shortly after the introduction of V8, people started taking JavaScript outside the browser more seriously.
This new runtime was incredibly powerful and fast, beating Ruby and Python, two of the most popular backend web languages at the time.
There was also the promise of sharing code between the backend & frontend, imaging not needing to rewrite your data validation or other logic if you wanted to run it server side & client side.
While strictly speaking, there were quite a few non-browser applications of JavaScript before this, Node.js was the first successful attempt at a general purpose runtime for JS.
It was now possible to run the equivalent of javascript my-script.js via node.
npm is an analogue to Python’s pip or poetry, helping to install packages and maintain environments.
As a runtime environment, node differs from the browser in significant ways.
It is a server-side framework, the person executing the code has a lot more control than a person that merely visits a webpage.
Code is not stuck in a sandbox, it can access the file system and other operating system features.
In 2024 Node.js is still the leading JS runtime for writing server-side applications. deno is a competitor that makes some interesting promises about security, but I don’t know anybody that is using it in production at the moment.
The most popular server-side web framework is express.js, but there is a healthy ecosystem of others. This would be used in lieu of Django or Flask on a team using SSJS.
Electron
V8 and Node.js have made it possible to write desktop apps in JS. Electron is a platform that basically renders an HTML canvas in an application.
Applications like Visual Studio Code and Slack are built on this, so they can leverage web technologies.
Browser JS in 2024
Despite many other uses today, JavaScript development is still driven by the browser.
The browser runtime has grown a lot of very useful features, notably a much improved replacement for the aging XMLHttpRequest in fetch, support for asynchronous functions, and lots of powerful new APIs to interact with 3D graphics, audio, location services, bluetooth peripherals, and much more.
Also, the browser dev tools, which you likely have used in web scraping, have integrated debuggers and other excellent tools right into the browser. This more than anything else has made writing frontend code less painful. If you’ll allow a brief editorial: It is a pretty neat thing that every browser, not just some special “developer edition” comes with a full suite of developer tools. This is fundamental to the spirit of the web as a participatory medium, not different tools for different people.
Browsers are much more compatible than they were, with far more cooperation between the browser vendors. Of course, occasionally one of the big players like Google will attempt to force through unpopular changes that are advantageous to them.
One of the threats to the continued openness of the web is browser monoculture.
Another recent development that’s changing how JavaScript is written is Web Components.
Web Components were inspired by the React framework, and allow developers to author custom HTML elements with cross-browser behavior.
That way instead of being constrained to the built-in form tags like <radio>, <checkbox>, <select>, <textarea> a developer can create their own interactive component and share it with others. Maybe a <usable-date-picker> instead of one that forces you to scroll from 1900 to your birth year for example.
See MDN: Web Components for more details.
Frontend Web Frameworks
With a more powerful JS runtime available via V8, the complexity of web applications grew.
This led to a flurry of new web frameworks like Angular, React, Vue, Svelte, and HTTPX.
Each of these has its own philosophy, but it is worth contrasting React with HTTPX to get a sense of the range of ideas.
React
React is a frontend web framework created by Facebook. It is built on a paradigm known as reactive programming, which is more special-purpose than functional/OO/etc. and in fact can be implemented in either style.
Reactive programming is focused on user interfaces, it allows you to declare components and how they should change when the user performs certain actions.
A simple component in React:
import React, { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
const increment = () => {
setCount(count + 1);
};
const decrement = () => {
setCount(count - 1);
};
return (
<div>
<h1>React Counter Example</h1>
<div>
<p>Count: {count}</p>
<button onClick={increment}>Increment</button>
<button onClick={decrement}>Decrement</button>
</div>
</div>
);
}
This creates a new <Counter/> element that can be incremented and decremented. In practice you would wire up much more complex behavior, but this shows how React is a blend of Javascript that returns HTML in a domain-specific-language known as JSX.
React is far from the only choice, another popular framework is Svelte. Many are built on similar paradigms, and for complex web UIs they can be incredibly useful.
For a website that doesn’t need a lot of custom behavior the browser doesn’t provide, some see them as overkill. Recently there has been a growing push back against these libraries and the complexity they bring in terms of tooling (React for instance usually depends upon JSX transpilation, addressed below.)
I am personally fond of the simpler philosophy of HTMX, which abstracts the most common interactions that people wind up writing in JavaScript into HTML-like attributes.
It is a much simpler library, easy to integrate with backend frameworks since it only really requires you to modify your HTML and provide additional backend responses:
<div id="counter">
<p>Count: <span id="count">0</span></p>
<button hx-post="/increment">Increment</button>
<button hx-post="/decrement">Decrement</button>
</div>
This snippet of code would mean that clicking either of the two buttons would do a behind-the-scenes POST to the /increment or /decrement API endpoints. These endpoints could return a new value for count.
Most of the actual work is done server-side, in Python or whatever you wrote your backend in, the frontend merely needs to be annotated with these hx- attributes which provide hooks for JavaScript provided by HTMX to add the appropriate behaviors.
React is a framework, it completely defines the way that your code will be written.
HTMX is more of a library, it requires minimal modifications to your existing code, you can pull it in on a project where needed instead of planning around it entirely.
Transpilation & Build Tools
React and lots of other ES frameworks (both client-side and server-side) use JS transpilers, this allows you to write modern ES and then the transpiler rewrites the code to work in particular runtimes (e.g. on a browser that doesn’t support the latest feature, or a phone’s more limited ES implementation).
This in turn means there is an added complexity in the tooling, you will find yourself using a tool like Parcel or Webpack to manage it all. These are build pipeline tools, converting one type of asset to another, for example:
- You write a React component using JSX and ES2024 features not yet supported in most browsers.
component.jsxtranspiles tocomponent.jswhich is a functionally equivalent piece of ES2020.- Since there are many such components, they get merged together into a file
all_components.js. - All installed libraries also get merged into a single file (this is done for the browser, since 1 request is typically better than many2).
- The code is often then minified, replacing variable names with shorter ones, removing comments, etc. This is partially done to speed up downloads since the resulting
all_components.jsis possibly several MB. This is also a means of obfuscating the code so others can’t read it.
This is an idealized idea of what a build pipeline does, but if you’ve never used a compiled language, this can feel like a lot.
The aforementioned linters are usually a part of this process too, ensuring high code quality.
Avoiding Build Tools
If you wish to avoid this complexity, you can take care to write browser-agnostic JS.
caniuse is a helpful resource for knowing what HTML/CSS/JS are supported by what browser versions.
One solution that’s easy to get started with is to use prebuilt/hosted versions of the JS libraries you wish to use.
This is typically done using CDNs, or content delivery networks. These host static files (JS and CSS) meant to be used by developers in building their sites.
This side-steps the complexity of setting up a build process, you simply link to the appropriate file and can write HTML right away.
<script src="https://d3js.org/d3.v7.min.js"></script>
<svg id="chart"></svg>
<script>
const data = [4, 8, 15, 16, 23, 42];
const colors = d3.schemeCategory10;
d3.select("#chart")
.selectAll("circle")
.data(data)
.join("circle")
.attr("cx", (d, i) => i * 50 + 25)
.attr("cy", 50)
.attr("r", d => d)
.attr("fill", (d, i) => colors[i]);
</script>
(this is included and executed directly on the page)
ESM vs UMD
Two competing standards for defining modules in JS emerged, and some libraries (like d3) offer both ECMAScript Modules (ESM) and Universal Module Definition (UMD).
If you are in a modern browser, you can use ESM via the new <script type='module'> tag, which allows import statements which are not permitted in the traditional <script type='javascript'> tags.
I am not steeped enough in the debate to make a coherent argument for UMD.
The Future of ES
TypeScript
The dream of server-side JS was to write the same data models, etc. on the server and use them on the client side as well, reducing code duplication across that boundary. A decade or so of experiences with it and some have concluded that a lot gets in the way of this in practice, and maybe it isn’t as important as it felt. TypeScript has some interesting approaches to this idea which has made it a popular replacement on a lot of teams. (I’ll address it a bit more below.)
TypeScript is both an attempt to fix some of the design flaws of ES, while also introducing strict typing.
That is instead of:
function greetPerson(person) {
console.log(`Hello, ${person.name}! You are ${person.age} years old.`);
}
// javascript objects are similar to dictionaries
const john = {
name: 'John Doe',
age: 30,
};
greetPerson(john);
You might write:
interface Person {
name: string;
age?: number;
}
function greetPerson(person: Person) {
console.log(`Hello, ${person.name}! You are ${person.age} years old.`);
}
const john: Person = {
name: 'John Doe',
age: 30,
};
greetPerson(john);
This is part of a broader trend in the last few years of programmers wanting more typing. Python is another language that has added typing constructs, and Rust’s popularity is tied to it’s robust type system.
TypeScript is mostly used by transpilation, teams write TS and compile it down to ES. Since transpilation was already a part of so many team’s pipelines, this is merely an additional step, not as much of a burden.
Some runtimes, like deno, support native TypeScript without compilation.
It is quite possible a browser will do the same at some point.
But there’s perhaps a different threat on the horizon to JavaScript’s dominance.
The Birth & Death of JavaScript
https://www.destroyallsoftware.com/talks/the-birth-and-death-of-javascript
A very popular talk from 2014 argued that in the not-so-distant future nearly all code would be written in a ES-derived language. It made an interesting case that since the web was here to stay, so was ECMAScript, so the language would keep improving until there was no need to have most other languages.
While it is true that the yearly pace of ES revisions has brought great improvements, I think that future is less likely today than it was 10 years ago.
Transpilation instead showed that we could continue to innovate by writing languages like JSX and TypeScript that transpile down to something the browser can use.
This raises the issue of the biggest threat to JavaScript’s dominance. An emerging technology called WebAssembly or wasm.
WebAssembly is a very low level language, analogous to assembly code that runs on processors. The advantages of a low level language is that it is easier for transpilers to target, converting Python to JavaScript is harder to do since the languages have different underlying semantics.
The low level language is intended to be robust enough that any language could compile down to wasm. This means it will be possible to write Python, Go, Rust, etc. that run in the browser. JavaScript has surely earned its place among them, but we may see that it is just one choice among many, or that a new dominant web language emerges.